KDD 2015 was held in Sydney, Australia.
A little more than one month ago, KDD 2015, the world’s most renowned data mining conference, was held in Sydney. A part of it was the IDEA workshop on interactive and exploratory mining, in which I had the opportunity to present our first research paper on Creedo [1]. Altogether, there were a lot of interesting things happening there that are very relevant to the topic of this web site. So it makes sense to have a post, in which I review some of them along with an extended discussion of some part of my talk. Here we go.
IDEA: The Knowledge Factory
The focus of IDEA (“Interactive Data Exploration and Analytics”) is, as the name suggest, principles and practices of interactive data analysis systems. In particular, it deals with holistic analysis systems that are composed from different data mining and visual analytics techniques with the goal of offering a more meaningful and more effective user experience than each of its parts individually.
This was the third time I attended this workshop after its initial event at KDD 2014 in Chicago and the second edition one year later in New York City at KDD 2015. Big thanks to the organizers for keeping up this great line of events. For me, the series already resembles more or less a mini-conference on its own with serious high level contributions, a little poster session, in the afternoon, and excellent and well-known keynote speakers. Regarding the latter, this incarnation featured Geoff Webb from Monash University and Jure Leskovec from Stanford.
Geoff’s keynote in particular provided a perfect “lead-in” to my presentation; firstly, simply because his popularity made sure that not only the last of approximately 80-100 seats was filled but also more crowd gathered in the back of the room; secondly, because of the topic he was presenting itself. He revisited “The Knowledge Factory [2]”—an early interactive knowledge discovery tool that he developed during the 90s. More specifically, Geoff’s web page refers to it as an “Expert System Development Environment”. In a nutshell, it supports a process, in which user and machine together construct an interpretable rule-set for the description/prediction of some target variable. For that, Geoff emphasized two scientific challenges, that were relevant back then as much as they still are today:
-
Finding a common language, in which user and machine can exchange information. To this end, The Knowledge Factory developed the paradigm of Case-based Communication. That is, the cases (examples, rows, data objects) serve as a common vocabulary. The system shows the user what cases are correctly/incorrectly covered and not covered by the current rule set and the user can respond by specifying cases that she considers a high/low priority to be corrected in the next iteration.
-
Evaluating the interaction model (and its different underlying policies). The claim of the system is about algorithms and human users acting effectively together. Thus, Geoff felt that the performance of the implementation had to be measured by a study with real users, which his group conducted successfully [3]. However, he went on in noting, that the amount of effort was very high, and, ultimately, this lead his group to somewhat abandon interactive systems in favor of other topics that were less demanding in moving them forward.
Both of these themes I took up in my talk in some form. The second is essentially the motivation for the central functionality of Creedo of user study automatization. The first is a specific incarnation of what I refer to below as the abstraction-gap between the sphere of the user and the formal sphere of the software system.

My Creedo message of empowerment 🙂
My Presentation: One System to Connect Two Worlds
The central motif of my talk (see slides here) was the gap that typically abounds in data mining research papers between
- the motivation, which is based on the natural language description of some real-world data analysis problem, and
- the technical contribution, which is typically developed and tested against a set of simplifying formal criteria.
This transfer of the problem into a formal domain is an essential step in solution development, because without it we could not tap into the formal methodology and knowledge repository of our discipline. Also it does not necessarily pose a problem as long as this abstraction gap between the two worlds is not too large and/or the theoretical formalization is widely used and well accepted. It may, however, be problematic in relatively young research areas that deal with subjects that are inherently hard to formalize—such as the users of interactive data analysis systems.
Since the scientific process demands some form of evaluation in order to move forward (read: “to get a paper published”), a particular effect is that the community shifts its attention to performance metrics that can be easier formalized and measured than the what would actually be the prime measure of performance according to the application domain. An example for this is the focus on computational complexity in the early days of Pattern Discovery, which produced a relative overabundance of papers presenting algorithm to solve the “frequent itemset mining problem” (listing all conjunctive expressions in a database with an occurrence frequency exceeding some fixed threshold), which in itself has little to no value in terms of actual knowledge discovery.
With this problem in mind, I went ahead with presenting how Creedo study designs are specifically designed to bridge this abstraction-gap and meaningfully re-connect this formal domain to the natural-language/real-world domain of the applications. How do they achieve this? Mainly though the definition of Creedo Tasks, which are a representation of a real-world problem that provides suitable facets of it to entities living on both sides of the abstraction-gap: the participants of a study, on the one side, and the analysis system(s) under investigation, on the other. Namely, a Creedo Task consists of:
- Human-readable instruction set of how and with what purpose to operate the data analysis system (capturing the natural language problem statement of the application more or less literally),
- Formal definition of states of the analysis system, in which the task is considered solved (e.g., “three patterns have been found by the user”),
Formal definition of what, in such a state, is exactly considered as the tangible result of the task (e.g., “all three patterns considered jointly as a pattern set”),
- Formal metrics for the evaluation of these results along with potentially human-readable instructions of how to apply them.
These tasks provide the context for running a study. Driven by the task instructions, participants operate a system until a solution state is reached. Creedo can then extract the results from these states and either evaluate them automatically or issue evaluation assignments to human evaluators based on the formal result metrics. Result evaluations can then be aggregated upwards to system performance metrics. This finally allows to compare different systems according to simple numeric quantities, and ultimately provide an extrinsic evaluation of a contribution as desired. That is, an evaluation that goes beyond the simplifying theoretical assumptions that have been posed initially to make solution development tractable and reach back to the original natural language problem statement.
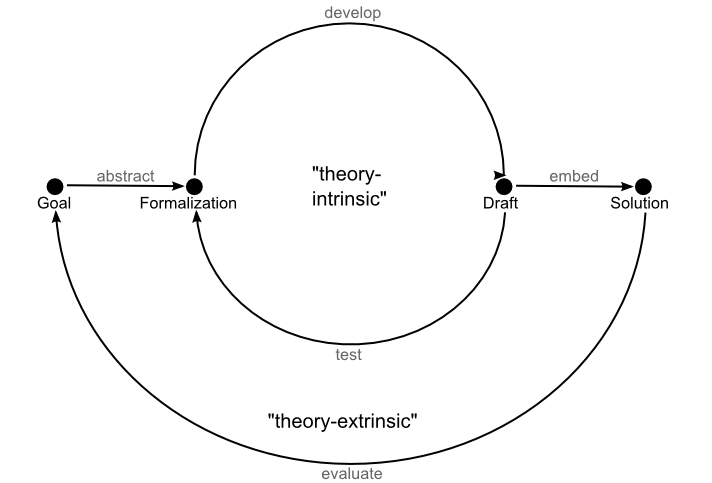
Extrinsic evaluations reach back over the abstraction-gap initially created to make solution development tractable.
Beyond IDEA: Rademacher Averages
Well, given my claim above about an arguably too high focus on computational complexity in Pattern Discovery, perhaps now it is time to put that into perspective. Clearly, after you have established what you have to compute, it is of course a relevant question to ask how to do it. Afterall, no knowledge discovery technique could be turned into actual usable technology if there wasn’t a software embodiment of it that is capable of processing input data relevant to a wide range of users. So beautiful algorithmic theory has a lot of purpose—especially, if it is capturing real input-requirements and is highly generic in terms of the number of specific computational problems it can be applied to.
So with this introduction, I would like to dive into a bit of algorithmic theory for closing this post. Namely, my favorite paper of the KDD 2015 main conference is “Mining Frequent Itemsets through Progressive Sampling with Rademacher Averages” by Matteo Riondato and Eli Upfal [4]. The paper describes how, Rademacher Averages, a tool from computational learning theory, can be applied to pattern discovery—more precisely to computing an approximate collection of frequent itemsets on a potentially very small subsample of the complete input dataset with controlled approximation guarantees (they also have a nice tutorial online).
Why is this important? First of all, you might end up with a much faster algorithm for computing frequent itemset for big datasets, which you could then use to compute, e.g., association rules, or any other knowledge discovery “end-product”. However, the results of the paper are far more general than that. In fact, the paper provides an efficient meta-algorithm for generating an (as small as possible) data sample that guarantees that the occurrence probabilities of all conjunctive pattern descriptors are approximately correct with high probability. This is huge, because a lot of utility functions in pattern discovery are actually functions of frequency counts of conjunctive expressions. For example, Matteo’s and Eli’s algorithm could be used just as much to compute the strength or lift of an association rule (no matter if you obtained it via the traditional workflow, a more modern algorithm like, e.g., by sampling, or even by hand like with MIME).
Therefore, I would love to see this approach as a general building block in integrated pattern discovery solutions. In particular I would love to see it in realKD as an encapsulated framework functionality that can be utilized by implementers of algorithms with a call as simple as measure.getApproximation(epsilon,delta). However, there are still some problems to be solved. For one, relatively strong bounds on frequency counts only induce relatively weak bounds on other functions, which in turn could lead to impractically large subsample sizes. So perhaps those functions could be targeted by a more direct application of learning theory. Also there are important pattern languages and utility functions that cannot simply be expressed as a function of frequency counts (e.g., applications’ favorite: Subgroup Discovery). In any case, this is rather a question of how much further can we push the limits, because already in its current this is something definitely worth including into any toolbox and I hope we can do something about this as soon as possible.
This is it for this time. I hope there was one interesting thing or two in it for you. Any comments/question either in the comment section below or private via e-mail are of course highly welcome.
References
[1]
![[pdf]](http://www.realkd.org/wp-content/plugins/papercite/img/pdf.png)
M. Boley, M. Krause-Traudes, B. Kang, and B. Jacobs, “Creedo-scalable and repeatable extrinsic evaluation for pattern discovery systems by online user studies,” in
Acm sigkdd workshop on interactive data exploration and analytics (idea), 2015, p. 20–28.
[Bibtex]
@inproceedings{boley2015creedo,
title={Creedo-Scalable and Repeatable Extrinsic Evaluation for Pattern Discovery Systems by Online User Studies},
author={Boley, Mario and Krause-Traudes, Maike and Kang, Bo and Jacobs, Bj{\"o}rn},
booktitle={ACM SIGKDD Workshop on Interactive Data Exploration and Analytics (IDEA)},
pages={20--28},
year={2015},
organization={ACM}
}
[2] G. I. Webb, “Integrating machine learning with knowledge acquisition through direct interaction with domain experts,”
Knowledge-based systems, vol. 9, iss. 4, p. 253–266, 1996.
[Bibtex]
@article{webb1996integrating,
title={Integrating machine learning with knowledge acquisition through direct interaction with domain experts},
author={Webb, Geoffrey I},
journal={Knowledge-based systems},
volume={9},
number={4},
pages={253--266},
year={1996},
publisher={Elsevier}
}
[3]
![[doi]](http://www.realkd.org/wp-content/plugins/papercite/img/external.png)
G. Webb, J. Wells, and Z. Zheng, “An experimental evaluation of integrating machine learning with knowledge acquisition,”
Machine learning, vol. 35, iss. 1, pp. 5-23, 1999.
[Bibtex]
@article{webb1999experimental,
year={1999},
issn={0885-6125},
journal={Machine Learning},
volume={35},
number={1},
doi={10.1023/A:1007504102006},
title={An Experimental Evaluation of Integrating Machine Learning with Knowledge Acquisition},
url={http://dx.doi.org/10.1023/A%3A1007504102006},
publisher={Kluwer Academic Publishers},
keywords={Integrated learning and knowledge acquisition; classification learning; evaluation of knowledge acquisition techniques},
author={Webb, GeoffreyI. and Wells, Jason and Zheng, Zijian},
pages={5-23},
language={English}
}
[4] M. Riondato and E. Upfal, “Mining frequent itemsets through progressive sampling with rademacher averages,” in
Proceedings of the 21th acm sigkdd international conference on knowledge discovery and data mining, 2015, p. 1005–1014.
[Bibtex]
@inproceedings{riondato2015mining,
title={Mining frequent itemsets through progressive sampling with Rademacher averages},
author={Riondato, Matteo and Upfal, Eli},
booktitle={Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining},
pages={1005--1014},
year={2015},
organization={ACM}
}